集群使用说明
分区信息
| 分区名称 | 包含节点 | 时间限制 | 备注 |
|---|---|---|---|
zen2 | cpu-epyc2-x | 用户规则 | 默认分区 |
zen4 | cpy-epyc4-x | 用户规则 | |
debug | analyze | 3 分钟 | 仅用于调试脚本 |
命令行使用说明
免密登录Linux
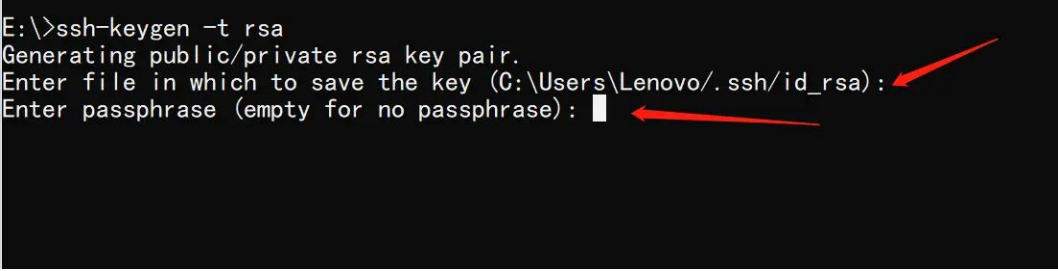
1 生成公钥文件(Windows 10)
按下 "Win + R" 键,输入 "cmd",然后在命令提示符中输入以下指令:
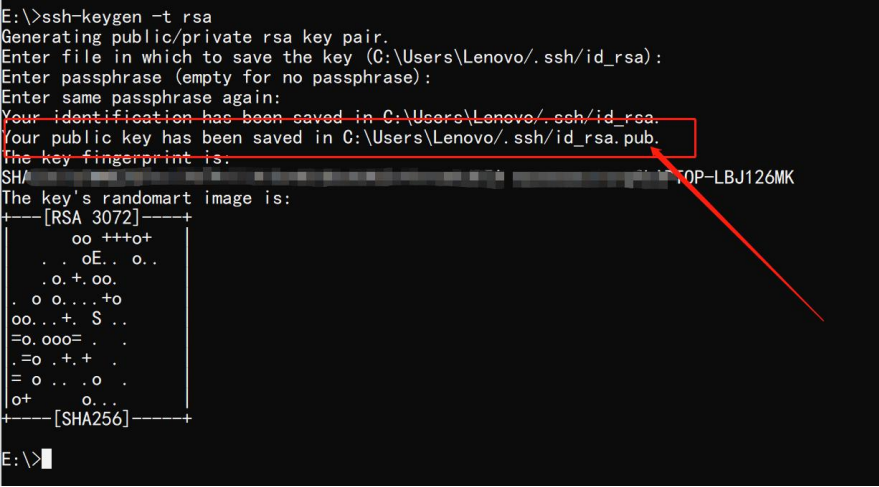
ssh-keygen -t rsa按回车以选择默认路径,并跳过密码设置。生成密钥成功的界面如下所示:
2 复制公钥文件(Windows 10/11)
找到公钥文件路径(例如 C:\Users\<用户名>\.ssh\id_rsa.pub):
然后在终端中输入以下命令将公钥复制到服务器:
scp C:\Users\<用户名>\.ssh\id_rsa.pub <用户名>@<登录节点 IP>:~/.ssh3 登录并写入公钥文件(Linux)
登录服务器并将公钥添加到 authorized_keys 文件:
ssh <用户名>@<登录节点 IP>
mv ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys修改文件权限:
chmod 600 ~/.ssh/authorized_keys
chmod 700 ~/.sshSlurm 常用命令
文档资源 slurm命令快速查阅slurm、PBS、LSF、SGE、LoadLeveler命令对照表
常用命令说明
| Slurm | 功能 |
|---|---|
| sinfo | 集群状态 |
| squeue | 排队作业状态 |
| sbatch | 作业提交 |
| scontrol | 查看和修改作业参数 |
| sacct | 已完成作业报告 |
| scancel | 删除作业 |
sinfo
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
zen2* up infinite 4 idle cpu-epyc2-[001-008]
zen4 up infinite 1 idle cpu-epyc4-[001-004]
debug up 3:00 1 idle login说明:
PARTITION:分区信息,zen2*中的*表示默认分区AVAIL:分区状态,UP 表示可用,其他状态表示分区不可用TIMELIMIT:分区时间限制,其中debug分区限时 3 分钟,仅用于脚本测试NODES:分区节点个数STATE:节点状态
节点状态表
| 显示 | 含义 |
|---|---|
drain | 节点故障 |
alloc | 节点全部占用 |
idle | 节点空闲 |
down | 节点离线 |
mix | 节点部分占用 |
squeue
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
404 zen2 sleep test R 0:03 1 cpu-epyc2-001
$ squeue -l
JOBID PARTITION NAME USER STATE TIME TIME_LIMI NODES NODELIST(REASON)
404 zen2 sleep test RUNNING 0:04 7-00:00:00 1 cpu-epyc2-001说明: 默认情况下,
squeue只会展示在排队或在运行的作业。 作业状态包含:R(正在运行)PD(正在排队)CG(即将完成)CD(已完成)
sbatch
参数说明
| Slurm | 含义 |
|---|---|
-n [count] | 并行计算组个数 |
-c, --cpus-per-task=[ncpus] | 每组并行计算中调用的CPU数 |
--mem=<size>[units] | 任务申请的内存 |
--ntasks-per-node=[count] | 每台节点的并行计算组个数 |
-p [partition] | 作业分区 |
--job-name=[name] | 作业名称 |
--output=[file_name] | 标准输出文件 |
--error=[file_name] | 标准错误文件 |
-t,--time=[dd-hh:mm:ss] | 作业最大运行时长 |
--exclusive | 独占节点 |
--mail-type=[type] | 通知类型,可选 all, fail, end,分别对应全通知、故障通知、结束通知 |
--mail-user=[mail_address] | 通知邮箱 |
--nodelist=[nodes] | 偏好的作业节点 |
--exclude=[nodes] | 避免的作业节点 |
--depend=[state:job_id] | 作业依赖 |
--array=[array_spec] | 序列作业 |
说明 以下文的 vasp 任务为例,其与提交脚本参数等价的命令行提交方式为:
sbatch -N 1 -n 128 -c 1 --mem=128G -p zen2 --hint=nomultithread sub-vasp.sh
示例任务文件
# 示例任务存放在 /public1/arch/common/examples
$ cp -r /public1/arch/common/examples ~/examples # 复制示例任务到home
$ ls ~/examples
01-vasp 02-lammps 03-array 04-conda 05-comsol 06-ansys sub-example.sh
$ cat sub-example.sh # 查看示例提交脚本
#!/bin/bash -l
#SBATCH --job-name=example # 任务名称:example
#SBATCH --partition=zen2 # 提交的任务分区:epyc2分区,参考sinfo输出
#SBATCH --nodelist=cpu-epyc2-001,cpu-epyc2-002 # 限制程序运行在cpu-epyc2-001,可删除
#SBATCH --ntasks-per-node=128 # 申请节点数:1
#SBATCH --mem=128G # 申请128G内存,单位K,M,G
#SBATCH --time=23:50:55 # 时间限制
#SBATCH --cpus-per-task=1 # 每个任务使用的CPU数:1
#SBATCH --output="slurm-%j.out" # slurm输出文件
## 上述行##号为注释,#为打开
##################分割##################
# run your job below
echo "1+1=2"注:
sub-example.sh文件解读: 任务申请资源 在 zen2 分区的指定节点列表 cpu-epyc 2-001, cpu-epyc 2-002 中申请 1 个节点来计算 1 个 job 此 job 使用 128 个 MPI 进程, 128 G 内存进行计算,限时 23 小时 50 分钟 55 秒。 每 MPI 进程使用 1 个 OMP 线程,slurm 输出到slurm-jobid.out文件 用户任务 执行echo "1+1=2"
下面针对具体软件进行任务提交演示
01-vasp
$ cd ~/examples/01-vasp/01-benchmark
$ tree # 查看文件结构
.
├── INCAR
├── KPOINTS
├── POSCAR
├── POTCAR
└── sub-vasp.sh
1 directory, 5 files
$ cat sub-vasp.sh # 查看vasp提交脚本
#!/bin/bash -l
#SBATCH --job-name=vasp # 任务名称:vasp
#SBATCH --nodes=1 # 申请节点数:1
#SBATCH --ntasks=128 # 总task数:128 -> MPI
#SBATCH --cpus-per-task=1 # 每个task使用的CPU数:1 -> OMP
#SBATCH --mem=128G # 申请128G内存,单位K,M,G
#SBATCH --partition=zen2 # 提交的任务分区:zen2分区
#SBATCH --output="slurm-%j.out" # slurm输出文件
## 上述行##号为注释,#为打开
##################分割##################
module load vasp
mpirun vasp_std
$ sbatch sub-vasp.sh # 提交任务后会返回一个纯数字的jobid
Submitted batch job 340
$ scontrol show job 340 # jobid替换成数字后运行可以查看作业信息
$ squeue # 查看作业排队情况
$ tail -f slurm-340.out # 持续打印任务输出
$ scancel 340 # 取消此作业
$ tail OUTCAR #等待任务计算完毕,即可查看此任务的运行时间Elapsed time
User time (sec): 141.045
System time (sec): 15.792
Elapsed time (sec): 166.496
Maximum memory used (kb): 246720.
Average memory used (kb): N/A
Minor page faults: 133133
Major page faults: 31
Voluntary context switches: 21125注:
sub-vasp.sh文件解读: 任务申请资源 在 zen2 分区申请 1 个节点来计算此job 该 job 使用 128 个 MPI 进程, 128 G 内存进行计算,使用用户限时。 每 MPI 进程使用 1 个 OMP 线程,slurm 输出到slurm-jobid.out文件 用户任务 加载 vasp 环境变量并运算
02-lammps
$ cd ~/examples/02-lammps/01-benchmark
$ tree # 查看文件结构
.
├── CuZr-test-100000.lmp
├── potentials # 赝势库文件
└── sub-lammps.sh
1 directory, 16 files
$ cat sub-lammps.sh # 查看vasp提交脚本
#!/bin/bash -l
#SBATCH --job-name=lammps # 任务名称:lammps
#SBATCH --nodes=1 # 申请节点数:1
#SBATCH --ntasks=128 # 总task数:128 -> MPI
#SBATCH --cpus-per-task=1 # 每个task使用的CPU数:1 -> OMP
#SBATCH --mem=128G # 申请128G内存,单位K,M,G
#SBATCH --partition=zen4 # 提交的任务分区:zen2分区
#SBATCH --output="slurm-%j.out" # slurm输出文件
## 上述行##号为注释,#为打开
##################分割##################
module load lammps
mpirun -- lmp -sf hybrid intel omp -in CuZr-test-100000.lmp
$ sbatch sub-lammps.sh # 提交任务后会返回一个纯数字的jobid
Submitted batch job 341
$ scontrol show job 341 # jobid替换成数字后运行可以查看作业信息
$ squeue # 查看作业排队情况
$ tail -f slurm-341.out # 持续打印任务输出
$ scancel 341 # 取消此作业
$ grep Performance slurm-341.out #等待任务计算完毕,即可查看此任务的Performance
Performance: 49.653 ns/day, 0.483 hours/ns, 574.687 timesteps/s, 62.066 Matom-step/s注:
sub-lammps.sh文件解读: 任务申请资源 在 zen4 分区申请 1 个节点来计算此 job 该 job 申请独占节点, 128 G 内存进行计算,即使用 192 个 MPI 进程,使用用户限时。 每 MPI 进程使用 1 个 OMP 线程,slurm 输出到slurm-jobid.out文件 用户任务 加载 lammps 环境变量 --sf hybrid intel omp: 指定了使用混合的 Intel 和 OpenMP 加速器。intel和omp分别表示使用 Intel 的优化库和 OpenMP 多线程并行化。 --in CuZr-test-100000.lmp: 指定了输入文件CuZr-test-100000.lmp。 注意:mpirun后需要添加--作为参数分隔符,否则会报错
03-array
$ cd ~/examples/03-array/01-echo_array_id
$ tree # 查看文件结构
.
└── sub-array.sh
$ cat sub-array.sh # 查看vasp提交脚本
#!/bin/bash -l
#SBATCH --job-name=array # 任务名称:array
#SBATCH --array=1-10 # 申请10个array任务
#SBATCH --nodes=1 # 申请节点数:1
#SBATCH --ntasks=4 # 总task数:4 -> MPI
#SBATCH --cpus-per-task=1 # 每个task使用的CPU数:1 -> OMP
#SBATCH --mem=4G # 申请4G内存,单位K,M,G
#SBATCH --partition=zen2 # 提交的任务分区:zen2分区
#SBATCH --output="slurm-%j.out" # slurm输出文件
## 上述行##号为注释,#为打开
##################分割##################
echo $SLURM_ARRAY_TASK_ID
$ sbatch sub-array.sh # 提交任务后会返回一个纯数字的jobid
Submitted batch job 342
$ tree
.
├── slurm-391
│ ├── 10.out
│ ├── 1.out
│ ├── 2.out
│ ├── 3.out
│ ├── 4.out
│ ├── 5.out
│ ├── 6.out
│ ├── 7.out
│ ├── 8.out
│ └── 9.out
└── sub-array.sh
1 directory, 11 files
$ tail slurm-391/*
==> slurm-391/10.out <==
10
==> slurm-391/1.out <==
1
==> slurm-391/2.out <==
2
==> slurm-391/3.out <==
3
==> slurm-391/4.out <==
4
==> slurm-391/5.out <==
5
==> slurm-391/6.out <==
6
==> slurm-391/7.out <==
7
==> slurm-391/8.out <==
8
==> slurm-391/9.out <==
9注:
sub-array.sh文件解读: 任务申请资源 此 job 包含 10 个 array job, 每个 array job 在 zen2 分区申请 1 个节点,4 个 MPI 进程 4G 内存,使用用户限时。 每 MPI 进程使用 1 个 OMP 线程,slurm 输出到slurm-jobid/array_id.out文件 用户任务 输出array id的值,用户可以通过此变量设计任务逻辑,批量提交任务
04-conda
命令说明
$ module load conda # 加载conda环境
$ conda init [bash|zsh]# 可选,写入配置文件中
$ conda create -n env_name python=3.11 # 创建名为env_name,python版本为3.11的conda环境
$ conda activate env_name # 激活env_name环境
$ conda deactivate env_name # 取消激活env_name环境
$ conda info # 查看环境信息06-ansys
.
├── 01-fluent #fluent提交示例
│ ├── smallCase.cas.h5
│ ├── test.jou
│ └── test.sh #slurm 提交文件
└── 02-lsdyna #lsdany提交示例
├── cut1.k
└── test.sh #slurm 提交文件
# 提交示例
sbatch test.shmodule 管理工具
集群软件以 module 形式供全局调用。常见的 module 命令如下
module load [MODULE...]: 加载模块
module avail 或 module av : 列出所有模块
module av intel: 列出含有 intel 名字的所有模块
module list: 列出所有已加载的模块
module show [MODULE]: 列出该模块的信息,如路径、环境变量等
$ module av vasp
--------------------------------- /public1/arch/epyc2/mfiles -----------------------------------------
vasp/6.3.2_openmpi_aocc_vtst_vaspsol vasp/6.4.2_openmpi_aocc (D)
--------------------------------- /public1/arch/epyc4/mfiles -----------------------------------------
vasp/6.3.2_openmpi_aocc_vtst_vaspsol vasp/6.4.2_openmpi_aocc
Where:
D: Default Module
If the avail list is too long consider trying:
"module --default avail" or "ml -d av" to just list the default modules.
"module overview" or "ml ov" to display the number of modules for each name.
Use "module spider" to find all possible modules and extensions.
Use "module keyword key1 key2 ..." to search for all possible modules matching any of the "keys".
$ module load vasp/6.3.2_openmpi_aocc_vtst_vaspsol # 此命令会自动加载相关依赖,无需用户手动控制
$ module load vasp输出说明: vasp/6.3.2_openmpi_aocc_vtst_vaspsol:vasp 的 6.3.2 版本,使用 opempi 和 aocc 编译器,带有 vtst 和 vaspsol 插件 vasp/6.4.2_openmpi_aocc (D):vasp 的 6.4.2 版本,使用 openmpi 和 aocc 编译器, (D)表示未指定版本时的默认加载模块